„és”: mindkét
feltétel teljesül
/* 3-mal és 5-tel is osztható */
if (szam % 3 == 0 && szam % 5 == 0)
printf("fizzbuzz\n");Vigyázat! Melyik feltétel is teljesül 15-nél???


Azért kell vigyázni, mert az egyes kiírások (fizz, buzz, fizzbuzz, szám) feltételei átfedik egymást. Ha egy szám 3-mal és 5-tel is osztható, akkor igaz az a kijelentés is, hogy 5-tel osztható. A feltételek nem zárják ki egymást! Így a programban két lehetőségünk van: vagy leírjuk azokat a feltételeket, amelyek teljesen kizárják egymást (pl. 3-mal és 5-tel is osztható; 3-mal igen, de 5-tel nem osztható stb.), vagy olyan vezérlési szerkezetet írunk, amely figyelembe veszi a halmaz–részhalmaz kapcsolatokat. Az utóbbi esetben az sem mindegy, hogy az elágazásokban melyik feltételt vizsgáljuk előbb. Ha a két oszthatóság együtt nem teljesül, még mindig lehet, hogy külön-külön valamelyik igen!
Az utóbbi elven működő megoldás:

#include <stdio.h>
int main(void) {
for (int szam = 1; szam <= 20; szam = szam+1)
if (szam % 3 == 0 && szam % 5 == 0)
printf("fizzbuzz\n");
else
if (szam % 3 == 0)
printf("fizz\n");
else
if (szam % 5 == 0)
printf("buzz\n");
else
printf("%d\n", szam);
return 0;
}Néhány C nyelvtani apróság a fenti programmal kapcsolatban. Mivel minden feltétel igaz és hamis ágában csak egy további utasítás van (egy következő if is egy utasításnak
számít), ezért itt nem volt szükség az utasítások {} blokkba helyezésére.
A C szabályai szerint az
else utasítás mindig az azt megelőző, legközelebbi if-hez tartozik. Ha ezt módosítani
szeretnénk, az természetesen lehetséges, az utasítások megfelelő {} blokkba helyezésével. Így:
if (feltétel1) {
if (feltétel2)
printf("akkor, ha feltétel1 és feltétel2");
} else
printf("akkor, ha nem feltétel1");Sokan egyébként az önálló utasításokat is blokkba teszik, és nem írnak a fentihez hasonló kódot. Néha hosszabb kicsit úgy, de sok előnye van.
Összesítsük a rendeléseket!
Írjunk programot, amely összegzi a fogyasztásunkat: a felhasználótól kapott pozitív, egész számokat összegez. Addig, amíg −1-et nem kap.
 + 3
+ 1 = ?
+ 3
+ 1 = ?
Összegzés tétele
összeg = 0 akkumulátor
CIKLUS AMÍG van még szám, ADDIG
szám = következő elem
összeg = összeg + szám
CIKLUS VÉGE
KI: összeg
Az „akkumulátor” változó az, amelyikben összegyűlik, akkumulálódik az eredmény. Ezt először nullázzuk, utána minden feldolgozott számot hozzáadunk. Minden iteráció végén az addig látott számok összegét fogja így tartalmazni. Ha esetleg egyszer sem ment volna be a ciklusba, akkor pedig nullát.
A bemeneti adatsor formátumát tekintve ez pont ugyanolyan, mint az előző pontban látott: egy végjeles sorozat.
Úgyhogy a tétel alkalmazásához a beolvasást kicsit át kell írni az előbb látott módon: az AMÍG van még szám ciklusfeltétel
while szam != -1-re átírása mellett a beolvasást is ki kell hoznunk a ciklus elé, illetve a ciklustörzs végére.
Így jutunk el a feladat megoldásához, amely lentebb látható.
nem egyenlő
a=a*b → a*=b
a=a+b → a+=b
stb.
#include <stdio.h>
int main(void) {
int szam;
printf("Kérem a számokat, -1: vége\n");
scanf("%d", &szam);
int osszeg = 0; // elején nulla
while (szam != -1) {
osszeg += szam; // összeg = összeg+szám
scanf("%d", &szam);
}
printf("Összeg: %d\n", osszeg);
return 0;
}Másik példa az „összegzésre”: faktoriális számítása
Mi a különbség az összegzés és a faktoriális számítása között programozási szempontból? Szinte semmi! Algoritmikai szempontból a kettő tökéletesen ugyanaz. Más a művelet, de ugyanaz az elv: ciklusban akkumulálunk. Csak lecseréljük:
- A kezdeti értéket 0-ról 1-re
- Az összeadást szorzásra
- A ciklust számlálásosra (1→n, ez előre adott hosszúságú sorozat), mert úgy szebb.
#include <stdio.h>
int main(void) {
int n;
printf("Melyik szám a faktoriálisa? ");
scanf("%d", &n);
int szorzat = 1;
for (int i = 1; i <= n; i += 1)
szorzat *= i; // szorzat = szorzat*i
printf("%d faktoriálisa %d\n", n, szorzat);
return 0;
}A karakterek kezelését ismerve már meg tudjuk oldani az „E betűk számlálása” feladatot.
„vagy”: valamelyik
feltétel teljesül
(elég az egyik)
#include <stdio.h>
int main(void) {
char c;
int db = 0;
int sikeresen = scanf("%c", &c);
while (sikeresen == 1) { // amíg !vége
if (c == 'e' || c == 'E')
db += 1; // ha megfelel, növeli
sikeresen = scanf("%c", &c);
}
printf("%d darab e betű volt.\n", db);
return 0;
}A program a két feltételét (kis „e” betű-e, nagy „E” betű-e) VAGY kapcsolatba hozva használtuk. Ez azt jelenti, hogy bármelyik megfelel számunkra. Akár kis „e” betű van, akár „E” betű, a számlálót megnöveljük. A pongyolán megfogalmazott feladatkiírás szólhatna úgy, hogy „számoljuk meg a kicsi és a nagy E betűket” – hiába tudjuk, hogy nem lehet egy betű egyszerre kicsi és nagy is.

A programok írásakor a logikai VAGY és logikai ÉS kapcsolatok közötti különbséget mindig pontosan át kell gondolni. Azért fontos ez, mert a köznapi beszédben a kettőt sokszor pont fordítva használjuk. Például elhangozhat egy tankörben a következő mondat: „Tegye fel a kezét, aki Budapesten és Debrecenben született!” Nyilvánvaló, hogy senki nem születhetett egyszerre Budapesten ÉS (logikai ÉS) Debrecenben. Egyszerűen csak ezt a gondolatot rövidítjük: „Tegye fel a kezét mindenki, aki Budapesten született, és tegye fel a kezét az is, aki Debrecenben született!” A matematikailag, és ezért a programjainkban is korrekt változat élő beszédben szokatlanul hangzana: „Tegye fel a kezét mindenki, aki vagy Budapesten, vagy Debrecenben született!”

Melyik a legmagasabb rakéta?
Olvassunk be a billentyűzetről a rakéták magasságát! Hány darabot? Kérdezzük a felhasználótól! Melyik volt a legnagyobb közülük?
Szélsőértékkeresés tétele
legnagyobb = első elem első CIKLUS AMÍG van még szám, ADDIG szám = következő elem többi HA szám > legnagyobb, AKKOR legnagyobb = szám FELTÉTEL VÉGE CIKLUS VÉGE KI: legnagyobb
Vigyázat! Az első „tippet” is a sorozatból kell venni! Általános esetben elvi hibás a legnagyobb=−1000 kezdetű vagy hasonló megoldás! (Ha az összes szám kisebb lenne −1000-nél, akkor hibás lenne az eredmény.)
A maximumkeresés C kódrészlete
printf("Hány szám lesz? ");
scanf("%d", &db);
printf("1. szám: ");
scanf("%lf", &aktualis);
max = aktualis; // az első külön
for (i = 2; i <= db; i += 1) { // a többit ciklusban
printf("%d. szám: ", i);
scanf("%lf", &aktualis);
if (aktualis > max) // nagyobb az eddigieknél?
max = aktualis;
}
printf("Maximum: %f\n", max);Feladat
Kérjünk a felhasználótól 10 számot, és utána írjuk ki őket fordított sorrendben!
Megoldás – sorminta???

int a, b, c, d, e, f, g, i, j, k;
scanf("%d", &a);
scanf("%d", &b);
scanf("%d", &c);
…
printf("%d\n", c);
printf("%d\n", b);
printf("%d\n", a);Mire lenne itt szükség?
Az eddigi programjainkban:
- Csak néhány nevesített változóval dolgoztunk, amelyeknek mind kitüntetett szerepe volt
- Nem tudtuk azt mondani, hogy „sok”
- Csak a beérkezés sorrendjében tudtuk feldolgozni az adatokat
Ami hiányzik:
- Jó lenne egyszerre több elemet is tárolni
- Az elemeket sorszámozva hivatkozni (első szám, második szám…), mert akkor egy ciklus végigmehetne az elemeken
- Az elemeket tetszőleges sorrendben elérni, mert akkor kiírhatnánk fordított sorrendben
Van néhány dolog, amit nem szabad csinálni a tömbökkel.
A tömb elemeit csak egyesével lehet kezelni.
int a[10], b[10];
a = b;for (i = 0; i < 10; i += 1)
a[i] = b[i];Az a=b értékadás helytelen voltának mélyebb okai vannak.
Erről később lesz szó.
A tömb méretét meg kell adni a program írásakor.
/* „elég nagy”? */
double tomb[];scanf("%d", &db);
double tomb[db];A tömbre mint fix méretű tárolóra kell gondolnunk elsősorban. Egy tömb
nem fog magától megnyúlni, sem összemenni: akkora marad, annyi számot tud tárolni, amennyit
a létrehozásakor megadtunk. Emiatt a meg nem adott méretű tömböt definiáló programsor
(int tomb[];) teljesen értelmetlen, és nagyon súlyos hibának számít.
A C nyelv újabb változata (C99) elfogadja azt, ha a tömb
méretét változóval adjuk meg, mint fent a scanf()-es példában. Ezzel azonban
óvatosan kell bánni, ilyet csak ellenőrzött körülmények között szabad csinálni.
Mi történik akkor, ha a felhasználó negatív számot ad meg? És akkor, ha egy óriási pozitív
számot, amennyi memóriája nincs a gépnek? Ezek olyan kérdések, amelyekkel most, a félév
elején még nem foglalkozunk, hanem majd később.
Párosak az egyik tömbbe, páratlanok a másikba.
int szamok[20] = { 3, -2, /* ... a számok ... */ };
int prs[20], ptln[20]; // ezekbe válogatja szét
int db_prs = 0, db_ptln = 0;
for (int i = 0; i < 20; i += 1) { // összes elem
if (szamok[i] % 2 == 0) {
prs[db_prs] = szamok[i]; // ha igaz rá, hogy…
db_prs += 1;
} else {
ptln[db_ptln] = szamok[i]; // ha nem igaz…
db_ptln += 1;
}
}
printf("%d páratlan, %d páros.\n", db_ptln, db_prs);Ez az algoritmus egy adott tulajdonság szerint szétválogatja a tömb elemeit. Amelyek rendelkeznek egy bizonyos tulajdonsággal (itt: párosak), azokat bemásolja az egyik tömbbe, a többit pedig a másikba (itt: páratlanok). Az eredeti tömb változatlan marad.

A két cél tömb mérete ugyanakkora, mint az eredeti tömbbé, hiszen előfordulhat, hogy az eredetiben pl. csak páros számok vannak. Minden egyes esetben, amikor valamelyik tömbbe beírunk egy elemet, akkor az ahhoz a tömbhöz tartozó számlálót megnöveljük. Először így a 0. indexű helyre kerül az elem, utána az 1. indexűre és így tovább.
A két számláló így egyben azt is tartalmazza,
hogy az egyes tömbökbe hány elem került – azaz hogy hány páros és hány
páratlan elem volt. A db_prs + db_ptln összeg a ciklus lefutása
után értelemszerűen az eredeti tömb méretével egyezik meg, mert mindegyik számnak
kerülnie kellett valahova.
Érdemes más programokban is ezt az elvet követni. Ezért is hasznos az, hogy az indexelés nullától indul: mert így a darabszám mindig megegyezik a következő elem indexével, ami pedig egyenlő azzal a tömbmérettel, amelyben elférnek az eddigi adatok.
Feladat: két kockával dobás összegét vizsgáljuk. Melyik összeg, milyen gyakran fordul elő?
A következő programban azt fogjuk megvizsgálni, hogy két dobókockával dobva, a két kockán látható számok összegének milyen eloszlása van. Mert az egy kockával dobással ellentétben ennél nem egyenletesen jön ki mindegyik összeg. A kockadobások szimulálásához véletlenszámokat fogunk használni.
A jól megírt programok determinisztikusak. Kérdés: akkor honnan lesznek véletlenszámaink?
A determinisztikusság azt jelenti, hogy egy adott programot ugyanazzal a bemenettel futtatva mindig ugyanazt a kimenetet kapjuk. A legtöbb esetben ez természetesnek tűnik, éppen ezt a megbízhatóságot várjuk a számítógéptől. Azonban bizonyos alkalmazásoknál ez korlátot jelent. Elképzelhetjük, elég unalmas lenne egy olyan kártyajáték, amelyben mindig ugyanazt a leosztást kapjuk. Mégis ha a számítógép determinisztikus természetű, hogyan lehetne olyan programot írni, amelynél nem minden futásnál ugyanaz az eredmény? Hogyan tudunk a programból feldobni egy pénzt, fej vagy írás, vagy kockával egy 1 és 6 közötti számot dobni?
A megoldás egy álvéletlenszám-generátor (vagy más néven:
pszeudovéletlenszám-generátor) alkalmazása. Ez egy olyan matematikai műveletsort jelent,
amelynek az eredménye egy össze-visszának tűnő számsor. Annyira össze-visszának, hogy az már
véletlenszerűnek fogadjuk el. Ha pl. az x=(5*x+1)%16 kifejezést újra és újra
kiértékeljük, az x változó a 1, 6, 15, 12, 13, 2, 11, 8, 9, 14, 7, 4, 5, 10, 3, 0,
… értékeket veszi fel, amelyben nem nagyon látunk szabályosságot. (Ha tovább folytatjuk,
akkor persze igen, mert a számsor elkezd ismétlődni.)
A C nyelv rand() függvénye a fentihez hasonló, de bonyolultabb módon előállított
véletlenszámokat ad, méghozzá a 0 és a RAND_MAX konstans közötti egész
számot. A RAND_MAX konstans értéke a C fordítónk típusától függ, és
számítógépenként változhat. Adott tartományban lévő számot legegyszerűbben egy osztás
maradékaként állíthatunk elő ebből. Ha például azt nézzük, hogy az előállított véletlenszám páros
vagy páratlan, pénzfeldobást szimulálhatunk:
if (rand() % 2 == 0)
printf("fej");
else
printf("írás");Kockadobást pedig úgy tudunk szimulálni, ha a véletlenszámot elosztjuk hattal, és az így kapott, 0 és 5 közé eső maradékhoz még egyet adunk:
kocka = rand()%6 + 1;Fontos, hogy az álvéletlenszámok determinisztikusak. Vagyis a program többszöri indítására
mindig újra ugyanaz a számsor áll elő. Ezt elkerülendő, a véletlenszám-generátort
inicializálni, azaz indítani kell. Az indítást az srand(x) utasítással
tehetjük meg, ahova az x helyére egy tetszőleges egész számot írhatunk. Ugyanaz az
x érték ugyanazt a számsort állítja elő újra, míg egy másik x érték
teljesen más számsort ad. Tehát már semmi más nem kell, csak egy olyan x érték,
amely a program minden futtatásánál más és más, mert ebből fog kiindulni a generátor. A probléma
megoldásához azt a trükköt szoktuk használni, hogy lekérdezzük a gép óráját: a
time(0) kifejezés az 1970. január 1. éjfél óta eltelt másodpercek számát adja.
Ezzel indítva a véletlenszám-generátort mindig más számsort fogunk kapni.
srand(time(0)); // a program elején egyszer!Ezt az inicializálást nem kell, sőt nem is szabad minden új szám generálásánál elvégezni,
hanem csakis a program futásának elején, egyszer kell megtenni! Az alábbi
program tíz egymás utáni kockadobás eredményét írja a képernyőre. Figyeld meg, hogy míg a
rand()%6 + 1 kifejezés többször is kiértékelődik a ciklusban, addig az
srand() csak egyszer, a program elején! Próbáld ki, mi történik akkor, ha a ciklus
belsejébe mozgatod az srand()-ot is!

#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main(void) {
srand(time(0)); // csak egyszer!
for (int i = 0; i < 10; i += 1)
printf("%d\n", rand()%6 + 1);
return 0;
}A rand() és az srand() függvény, továbbá a RAND_MAX konstans
használatához az stdlib.h fájlt kell a programkód elején beilleszteni. A time()-hoz a time.h
szükséges. A time() működéséről és az ott lévő 0 szerepéről később lesz szó.
double pi = 3.14; // inicializált változó
int i, osszeg; // inicializálatlan változóHa nem kap kezdeti értéket, inicializálatlan lesz → memóriaszemét

Az inicializálatlan változók
- Súlyos hiba egy inicializálatlan változó értékét használni!
- Lehet, hogy nulla, lehet, hogy nem. Lehet, hogy mindig más az értéke, lehet, hogy nem. Lehet, hogy működik a program, lehet, hogy nem
- Misztikus, megjósolhatatlan hibajelenségek!
Vigyázat: a lentiek nem jelentik azt, hogy görcsösen adjunk kezdeti értéket minden
változónak, akkor is, ha felesleges! Például egy ciklusváltozót felesleges inicializálni a
létrehozásakor, hiszen a for fejlécében úgyis fog értéket kapni. Egy összegzést
végző programrész osszeg=0 utasítását is érdemes a ciklus elé tenni közvetlenül,
hiszen ahhoz a programrészlethez tartozik logikailag!
Ezt a kódrészletet mindenki ki tudja próbálni a saját gépén. A legmeglepőbb dolgok történhetnek, mivel a működése az inicializálatlan változók miatt nem definiált.
#include <stdio.h>
int main(void) {
/* inicializálatlan */
int t[15];
for (int i = 0; i < 15; i += 1)
printf("%d\n", t[i]);
return 0;
}Túlindexelés: súlyos hiba!
- A C nem ellenőrzi a megadott tömbindexeket
int t[10]tömb túlindexelése:t[-1], t[10], t[234]- Misztikus hibák, elvesző változóértékek, lefagyó programok
Az indexhatárok nem ellenőrzésének az oka egyszerű: a hatékonyság. A C nyelv sok modern programozási nyelvvel ellentétben arra való, hogy a lehető leggyorsabban futó programokat írjuk vele. A helyesen megírt programban sehol nincsen tömb túlindexelés, ezért felesleges is lenne a program futása közben ellenőrizni, hogy van-e benne ilyen hiba! A helyes program írása így aztán nem másnak a feladata, mint a programozónak.
„Ki itt belépsz, hagyj fel minden reménnyel.”
Nem definiált működés (undefined behaviour): hibás program, nincs meghatározva, hogy minek kellene történnie. Nincs garantálva semmi.
Ezt is érdemes kipróbálni.
#include <stdio.h>
int main(void) {
double t[10];
int a = 1, b = 2, c = 3;
printf("a=%d\nb=%d\nc=%d\n", a,b,c);
/* túlindexelés */
t[-1] = 0.2;
t[10] = 0.3;
printf("\n");
printf("a=%d\nb=%d\nc=%d\n", a,b,c);
return 0;
}
| kifejezés | jelentés |
|---|---|
3.14
| tizedespont, a π közelítő értéke vessző, elválasztás, pl. pow(3, 14)=314
|
x == y
| vizsgálat: x egyenlő-e y-nal értékadás: x legyen egyenlő y-nal |
x = b
| x vegye fel a b változó értékét x legyen a b betű karakterkódja |
x = 1
| x legyen 1 x legyen az 1-es számjegy karakterkódja |
printf("%d", 65)
| írd ki 65-öt, mint szám: "65" írd ki a 65-ös kódú karaktert: "A" |
"a"
| szöveg (sztring), amely egy betűt tartalmaz egyetlen karakter |

Az értékadás és az egyenlőségvizsgálat keverése miatt gyakran szokták
tanácsolni, hogy a feltételeket fordítva írjuk. Így nem lehet összekeverni a kettőt, hiszen
ebben a kódrészletben = értékadás használata esetén szintaktikai hibát kapunk, ami
fordítási hibához vezet. Sajnos a fordított feltétel az olvashatóságot csökkenti, néha zavar a
kód megértésében. Ezért mi nem javasoljuk a használatát. A programozó folklór egyébként ezt a
stílust Yoda-feltételnek nevezi, mert Yoda az eredeti Csillagok háborúja szinkronban így beszél
(pl. „if blue is the sky”-t mond „if the sky is blue” helyett.)
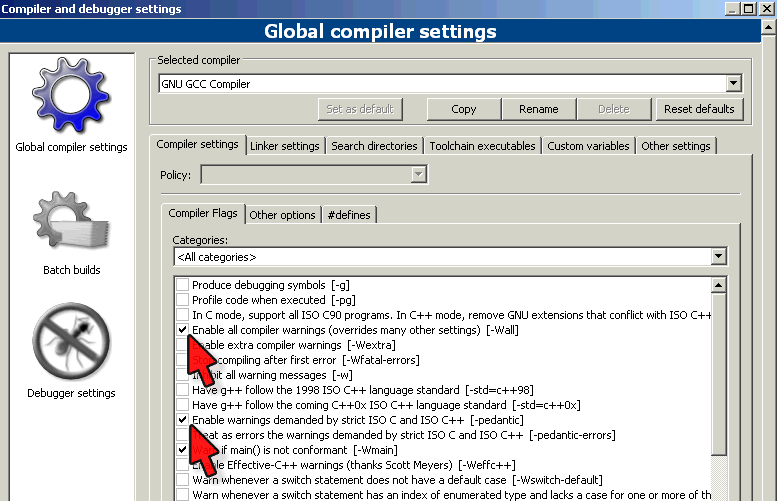
- Enable all compiler warnings (-Wall)
- Enable warnings demanded by strict ISO C (-pedantic)
- treat warnings as errors (-Werror)
A Code::Blocks Settings menüjében találunk egy Compiler and
debugger… menüpontot. Ezt megnyitva a fordítóprogram beállításaihoz
jutunk. A fent látható két opciót nagyon erősen javasolt
engedélyezni az otthoni gépeteken. Ilyenkor ugyanis a fordító minden gyanús,
szokatlan kódrészletre figyelmeztetést ad (-Wall), illetve a nem szabványos,
esetleg más fordítókkal nem működő nyelvi fordulatokat nem engedi használni
(-pedantic). Ezeket beállítva sokkal hatékonyabb, könnyebb a tanulás és a
gyakorlás! Például az előbb említett x=y és x==y
összekeverésére is legtöbbször figyelmeztetni tud.
Kezdő programozók jó barátja a kezeld a figyelmeztetéseket hibaként (-Werror) kapcsoló. Ekkor nem is készít futtathatót a fordító, amíg figyelmeztető üzenet van. Ennek azért van jelentősége, mert a megszokott Build & run indítással a fordító figyelmeztető üzeneteiről nem értesülünk, csak a hibás működésű futó program jelzi a problémát. Ezt is a fenti ablakban tudjuk beállítani, de ehhez nincs jelölőnégyzet, hanem az Other options fülön kell beírni. Nagyon ajánlott, a HSzK gépein is be van állítva.