Rémtörténet a karakterkódolásokról
Czirkos Zoltán, Dobra Gábor · 2022.05.25.
Ékezetes betűk, szövegek kódolása és megjelenítése a programokban. Javasolt olvasmány azoknak, akik szeretnék a nagy házijukban megoldani a magyar ékezetes szövegek helyes kezelését.

Az ékezetes betűk kódolásával máig gondok vannak. Sokféle szabvány létezik arra, hogy mely ékezetes betűt milyen számkóddal jelölünk, ami azért nehéz ügy, mert ezek a kódtáblázatok általában egymással inkompatibilisek.
A probléma ugyan elméletben megoldott, létezik olyan karakterkódolás a Unicode szabvány részeként, amely a világ (majdnem) összes nyelvének (majdnem) összes írásjeléhez karakterkódot rendel, mégis rendszeresen találkozunk árvíztûrõ tükörfúrógépekkel (meg ĂĄrvĂztĹąrĹ tükörfúrógépekkel) még nyomtatott szövegekben is. Ennek oka sokszor a programozók figyelmetlensége. Sajnos a Windows is hírhedten hibás és hiányos ilyen téren.
A karakterkódolási szabványok követésével és a programok helyes beállításával a problémák megszüntethetők. Legtöbbször csak egy-két függvényhívásról van szó. Ha a rémtörténet nem érdekel, szeretnél jól aludni, vagy csak azért vagy itt, mert az ékezetes szövegek nem látszanak jól a nagy házidban, akkor lapozz az oldal legaljára, a receptekhez.
Az angol nyelvben használt, ékezet nélküli betűkhöz az ASCII kódolás terjedt el. Erről előadáson is volt szó. Egykor voltak más kódolások is, de a ASCII mára gyakorlatilag egyeduralkodóvá vált.
A nyugat-európai nyelvekhez (pl. a franciához) használják ennek a Latin-1, vagy más néven ISO8859-1-es bővítését. Ez az ASCII kódolás 128 kódját újabb 96 karakterrel egészíti ki a 160-255 tartományban, így ez már 8 bites. Ebben sajnos nincsen benne a magyar ő és ű betű. A testvérében, a Latin-2-ben (ISO8859-2) benne van, így ezzel bármilyen magyar szöveg leírható. Ebben a magyar ű betű helyén a Latin-1-esben û van, az ő helyén pedig õ. Ezért találkozni néha ilyenekkel: árvíztûrõ tükörfúrógép, amikor egy Latin-2 kódolással megadott sztringet Latin-1 kódolásúnak gondol egy program, vagy esetleg egy betűtípusban szerepel helytelenül, hogy melyik „alakzat” (graféma) melyik karaktert is jelenti.
A Latin-2-höz hasonló kódolást használ a Windows a szövegfájloknál (Windows-1250). A konzol ablakban sajnos egy másikat (IBM-852), amely a Latin-1-2-re egyáltalán nem hasonlít. Ezek a kódolások a lenti képeken láthatóak.



A karakterkódolások közötti inkompatibilitás problémája akkor jelentkezik, amikor a programunkban ékezetes szöveget szeretnénk
kiírni. Ha azt mondjuk a Code::Blocksban (Windowson), hogy printf("ő"), a keletkező sztring a 0xF5,
0x00 bájtokból áll: az ő kódja és a lezáró nulla. De a konzolablakban a 0xF5 a paragrafus
jel § karakterkódja! Ha kérünk egy sztringet, az viszont helyesen fog megjelenni kiíráskor, mivel a programunkban
történő beolvasáskor már az IBM-852 szerinti kódok vannak:
═rd be, hogy teniszŘt§! teniszütő Ezt Ýrtad be: teniszütő
Ha a konzol ablakhoz kiválasztunk egy olyan betűtípust, amely tartalmazza a megfelelő ékezetes karaktereket (pl. a Consolas és a Lucida Console ilyen), és a parancssorban a program futtatása előtt átváltjuk a karakterkódolást arra, amelyik kódolással a forráskódot is elmentettük, helyesen jelenhet meg a szöveg. Ehhez a lenti recepteknél a konzolos programokhoz írt útmutatót kell használni.
A többnyelvű szövegek nem írhatóak le a fenti kódolásokkal. Nem csak az a baj, hogy egy cirill vagy japán betűk nem szerepelnek bennük, hanem például még egy latin betűs útikönyvvel is gondban vagyunk! A Latin-1-ben nincs ő, a Latin-2-ben nincs ø, ezért ez a mondat nem írható le egyikkel sem: Dánia fővárosa København.

A '80-as évek vége táján felmerült, hogy létre kellene hozni egy olyan kódtáblát, amely a világ összes nyelvének összes
karakterét tartalmazza, mert akkor nem lesz ilyen gond. Ez lett a Unicode szabvány része. Mivel azonban az összes létező írásjelek
256-nál többen vannak, ebben egy karaktert már nem egy bájttal, hanem egy nagyobb számmal jelölnek. Aminek pedig az a
következménye, hogy egy Unicode sztring közvetlenül nem jelenhet meg char tömbként a C programunkban, mert a
char a C fogalmai szerint bájtot jelent.
A Unicode szabványban a legtöbb karakter elfér 16 biten, de újabb verziókban akár még nagyobbak lehetnek. Míg pl. az ő betű vagy az € jel ábrázolható 16 bites számmal (karakterkódjuk 337 és 8364), addig más jelekhez, pl. emoji-khoz 216, azaz 65536 feleti szám tartozik (😺 kódja 128570, 🤡 pedig 129313).
Az egybájtos karakterkódokról Unicode-ra átalakítani egy szöveget nagyon könnyű; egy 256 elemű tömbben eltárolhatjuk, melyik kódból mi lesz. Az egyes kódolásokhoz (Latin-1, Latin-2 stb.) azonban eltérő táblázatok tartoznak. A visszaalakítás nem ilyen egyszerű, mert bár technikailag könnyen megvalósítható, könnyen előfordulhat, hogy olyan karaktert kell átkódolni, ami a cél kódtáblában nem létezik. A halmazelméletben használt ∉ „nem eleme” szimbólum például semelyik fenti táblázatban nem létezik.
Fölmerül még egy probléma az egy bájtnál nagyobb számok miatt. Egyes számítógéptípusok úgy tárolják a 16 bites számokat –
amelyeket két 8 bites bájtként kell elhelyezni a memóriában –, hogy az alsó 8 bitet írják előbb, és utána a felső 8-at. Vagyis
előbb a kicsit (little endian). Más gépek meg épp fordítva, előre veszi a felső 8 bitet, és utána, a következő memóriarekeszbe
pedig az alsó 8 bitet (big endian). Ez egészen addig nem gond, amíg két, eltérő típusú számítógépnek nem kell kommunikálnia
egymással. Viszont ha ezek az Interneten keresztül adatot küldenének egymásnak, vagy szeretnék olvasni az egymás által kiírt
fájlokat, akkor már figyelni kell arra, hogy esetleg nem ugyanazt a bájtsorrendet használják – különben amit az egyik
0xFCE2-nek mond, azt a másik 0xE2FC-nek fogja értelmezni, és fordítva. Nagyobb számok (pl. 32 bites
integerek) esetén hasonló a helyzet.
Ezért a Unicode kódolású szövegekben el szoktak helyezni egy ún. BOM (byte order mark, bájtsorrend jele) karaktert, amelynek a
kódja 0xFEFF. Ha a szöveget olvasó számítógép egy 0xFEFF kódot talál a szövegben, akkor tudja, hogy annak
bájtsorrendje megegyezik a sajátjával. Ha azonban egy 0xFFFE számot lát (amely szándékosan semmilyen karakternek nem
kódja), akkor tudja, hogy minden számban meg kell cserélnie a felső és alsó nyolc bitet.
A BOM-mal kiegészített, „HELLO” szöveget tároló fájlok bájtsorrendtől függően így nézhetnek ki (16 bites tömbelemeket feltételezve):
FE FF 00 48 00 45 00 4C 00 4C 00 4F
FF FE 48 00 45 00 4C 00 4C 00 4F 00
Az alábbi kódrészletek a nagy házikban szabadon felhasználhatóak.
Linux konzol ablak és fájlok
Nincs különösebb teendő, minden működik magától. A legtöbb Linux UTF-8 kódolást használ a parancssori ablakokban és a fájlokban
is, úgyhogy semmi extra teendő nincsen, rögtön működnek az ékezetes betűt használó programok. Egy dologra kell figyelni, hogy az
UTF-8-ban karakter≠bájt! Mivel az ékezetes betűk kettő, egyéb karakterek akár több bájton lehetnek kódolva, a sztringek indexei
elcsúsznak, és hosszaik nem egyeznek meg az strlen() által adottakkal. Például strlen("teniszütő") értéke
11. Ez 9 karakter, 11 bájt hosszú sztring, 12 bájtnyi memóriafoglalás. (Az utf8_strlen() függvény megírása házi
feladat.)
Windows konzol ablak – Windows-1250 kódolással

Bár a Windows már az XP verzió óta támogatja az 1993 óta létező UTF-8 szabványt, alapbeállítás esetén még mindig nem használja. A Windows 10-ben az UTF-8 támogatása konkrétan hibás, így kénytelenek vagyunk a múltat konzerválni, és Windows-1250 karakterkódolást használni.
A teendők ehhez:
- A parancssori ablakot úgy beállítani, hogy Consolas, vagy egy másik, Unicode-kompatibilis betűtípust használjon. Az ablak ikonjára klikk, Alapértelmezések (Defaults), Betűtípus (Font). A következő ablak megnyitásakor jó lesz.
- Figyelni kell arra, hogy a forráskódok Windows-1250 kódolással legyenek elmentve. Ehhez a Code::Blocks Edit / File encoding menüpontja alatt a System default lehetőséget kell kiválasztani. Ha van olyan korábban létrehozott fájlunk, amiben már vannak ékezetes karakterek, csak nem jól jelennek meg, át kellhet konvertálni a fájlt, annak megnyitásával és újbóli elmentésével.
- Ha a program használ szöveges adatfájlokat, azokat a fentiekhez hasonlóan Windows-1250 kódolással kell elmenteni.
- A program elején kiválasztani ezt a kódolást a lenti kódrészlettel.
A konzol ablak kódlapjának beállítása megtehető két függvényhívással: SetConsoleCP(1250) és
SetConsoleOutputCP(1250). Az egyik a bemeneti kódlapot állítja be, a másik pedig a kimeneti kódlapot. (Hogy miért tér
el a beolvasáskor és kiíráskor használt karakterkódolás a Windowsban, miért kell ezeket külön beállítani, egy örök rejtély a világ
számára.) Vigyázat, ezek nem szabványos függvényhívások! Illik őket #ifdef-ek közé tenni, hogy maradjanak
hatástalanok, ha más operációs rendszeren fordítja valaki a programot. A két függvényhívást elég a program elején egyszer megtenni
(praktikusan a main() elején valamikor), többször már nem.
#include <stdio.h>
#ifdef _WIN32
#include <windows.h>
#endif
int main(void) {
#ifdef _WIN32
SetConsoleCP(1250);
SetConsoleOutputCP(1250);
#endif
printf("Írd be, hogy teniszütő!\n");
char s[100];
scanf("%s", s);
printf("Ezt írtad be: %s.", s);
return 0;
}A Windows-1250 kódolással mentés könnyen ellenőrizhető. Csak meg kell vizsgálni, hogy egy adott betű karakterkódja egyezik-e az általunk elvárttal:
#include <assert.h>
int main(void) {
assert((unsigned char)'ő' == 245);
}Ügyelni kell arra, hogy bizonyos karakterek (pl. ☺) nem jeleníthetők meg ezzel a kódolással. Ilyenkor a Code::Blocks
automatikusan átáll UTF-8-ra, különben el sem tudná menteni a fájlt! A Code::Blocks-nak néha az ő betűvel is gondja
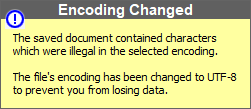
akad, pl. angol nyelvű Windowson. Ha mentés közben a lentebb látható figyelmeztető ablak ugrik fel, akkor a Windows nincs magyar
nyelvűre állítva, vagy esetleg a program valamelyik sztringje olyan karaktert tartalmaz, ami nem elmenthető ilyen formában.
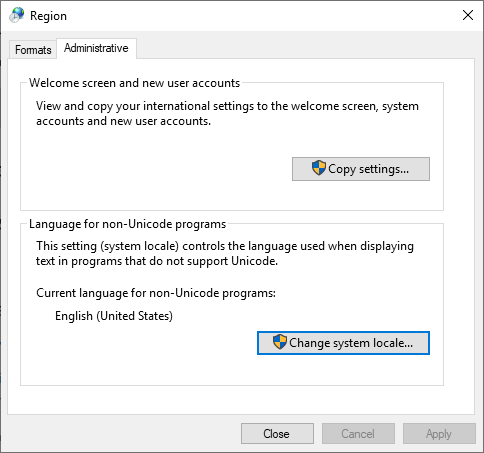
A magyar nyelvűre állításhoz a vezérlőpult területi beállításai (Region) között kell kutakodni.
SDL – UTF-8 kódolással

Az SDL-es programoknál érdemes inkább UTF-8 karakterkódolást használni. Az SDL_TTF
könyvtár TTF_RenderUTF8_Blended és hasonló függvényei közvetlenül is támogatják ezt a kódolást.
Arra kell csak figyelni, hogy a program forráskódja és a szöveges adatfájljai is UTF-8 kódolással legyenek elmentve. Ehhez a Code::Blocks Edit / File encoding menüpontja alatt az UTF-8 lehetőséget kell kiválasztani. Ha van olyan korábban létrehozott fájlunk, amiben már vannak ékezetes karakterek, csak nem jól jelennek meg, akkor át kellhet konvertálni a fájlt, annak megnyitásával és újbóli elmentésével.
Az UTF-8 kódolással mentés könnyen ellenőrizhető:
#include <assert.h>
#include <string.h>
int main(void) {
assert(strlen("ő") == 2);
}UTF-8 BOM karakter a Windows szövegfájljaiban
Az UTF-8 kódolás gyakorlatilag a Unicode karakterek kódjait használja, azoknak egy kényelmesebb ábrázolási módja. Azt azonban nem köti meg az UTF-8 szabvány, hogy a Unicode fájlok elején lévő BOM-ot tartalmaznia kell-e egy UTF-8 fájlnak. Mivel a bájtok sorrendje kötött, teljesen felesleges jelezni a bájtsorrendet, így a legtöbb program nem használ UTF-8 kódolás esetén BOM-ot.
Néhány windowsos program (pl. Notepad) ennek ellenére elhelyezi ezt a bájtot a fájlok elejére, ezzel számos problémát okozva. Sok program erre nincs felkészítve, hiszen logikátlan a dolog. Ironikus módon az Internet Exporer is ilyen, pedig az is a Windows része.
A BOM kódja 0xFEFF, ami a 0x0800-0xFFFF tartományba esik, így UTF-8 reprezentációja három bájtos: EF BB
BF. Pl. az „árvíztűrő” szöveg egy szövegfájlban:
C3 A1 72 76 C3 AD 7A 74 C5 B1 72 C5 91 (UTF-8) EF BB BF C3 A1 72 76 C3 AD 7A 74 C5 B1 72 C5 91 (UTF-8 + BOM)
Ha ilyet látunk a fájl elején, egyszerűen el kell dobni az első három bájtot.
char buf[3];
fscanf(fp, "%3c", buf);
if (memcmp(buf, "\xEF\xBB\xBF", 3) != 0) /* ha nem bom-mal kezdődik a fájl */
fseek(fp, 0, SEEK_SET); /* vissza az elejére */
/* ... a fájl kezelése ... */